
Kafka Series I: Kafka Overview
A intro and look into Kafka Producer. Using Kafka version 2.8

Overview
In this article, I take the liberty of assuming the reader knows the basics of Kafka and its basic concepts. Here is a quick introduction.
Kafka's official website defines itself as follows:
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Let's expand to summarize:
As a Message Queuing System: Kafka is a robust, distributed message system with partitioning and multi-copy replication capabilities. It facilitates the establishment of real-time data streaming pipelines, reliably transporting data between various systems or applications. What distinguishes Kafka from other message queuing systems is its heavy reliance on batch processing and asynchronous methodologies. This design allows it to process an extremely high volume of messages — up to tens of millions per second.
As a Stream Processing Platform: It also serves as a dependable data source for various popular stream-processing frameworks. Additionally, it provides a comprehensive in-built stream processing framework, which supports a wide array of operations including windowing, connection, transformation, and aggregation. In the realm of big data and stream computing, Kafka boasts one of the best compatibility profiles with surrounding ecosystems, thanks to its comprehensive feature set.
Kafka is widely used in two scenarios:
Message Queuing : Build real-time streaming data pipelines to reliably get data between systems or applications
Data Processing : Build real-time streaming data processing programs to transform or process data streams
Workflow of Kafka
In general, Producers(clients) constantly send data to Kafka, which in turn is picked up by consumers at defined intervals. The Kafka internally keeps track of the progression of what messages have been consumed.
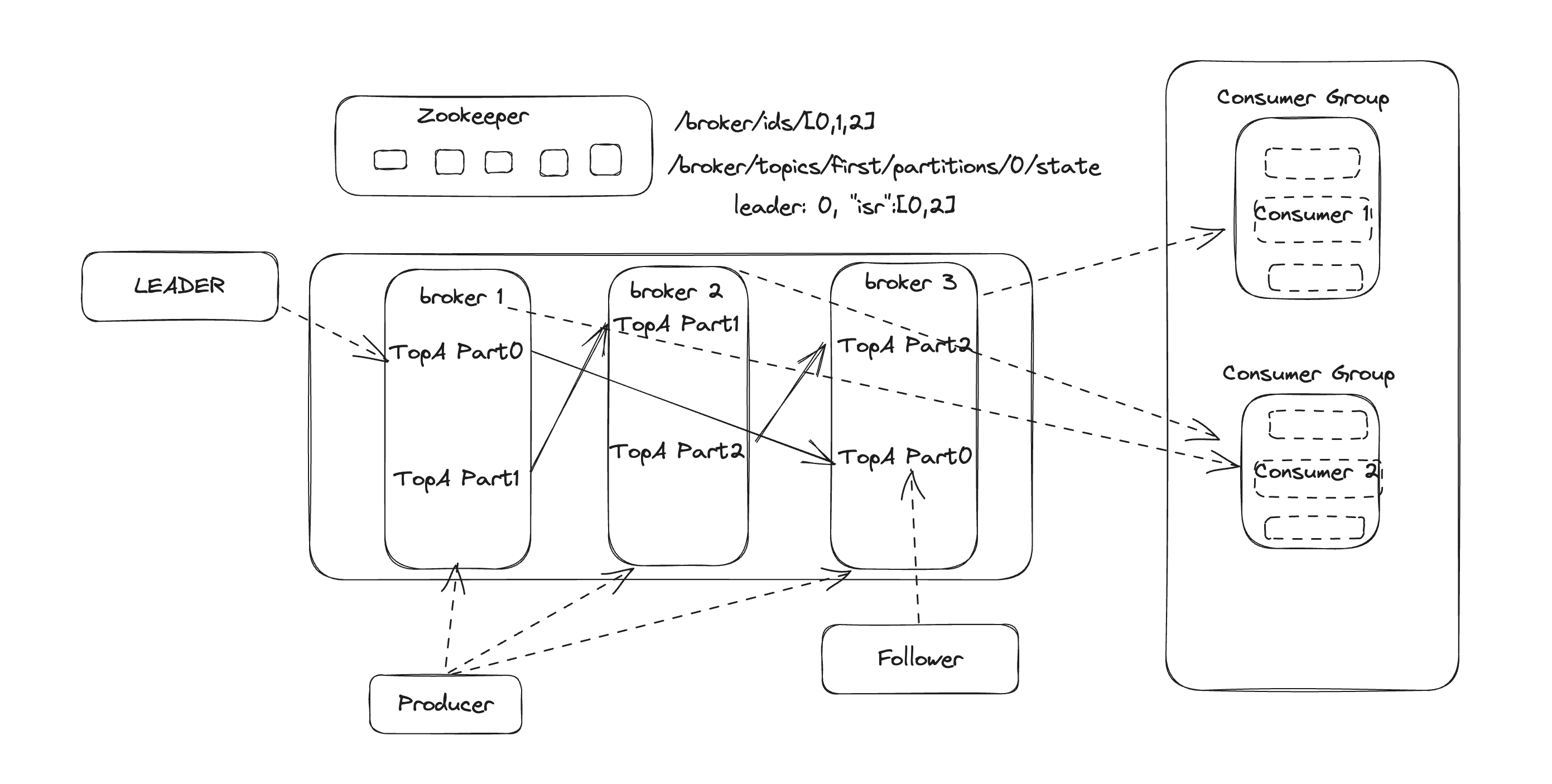
Here are some keywords, that appear in the above diagram.
Producer (producer): the creator of the messages that are sent to Kafka.
Consumer (consumer): the consumer of messages, from kafka. They typically listen to subscribed topics.
Group (consumer group): Each consumer will have a GroupId. If multiple consumers have the same GroupId, then it means they belong to the same Group. A GroupId can be regarded as a consumer, and they will not consume the same message repeatedly
Broker (agent): Here, it can be understood as a standalone Kafka instance. To maintain high scalability, the Kafka cluster can horizontally expand, thus having many Brokers to increase its concurrent processing capabilities
Topic: Producer sends messages to a specific topic, and the Consumer consumes messages by subscribing to a specific Topic (topic)
Partition (partition): Partition is a component of the Topic. A Topic can have multiple Partitions, and Partitions under the same Topic can be distributed on different Brokers. So, an individual Partition is confined to a single Broker and does not span multiple Brokers.
Offset (the offset of the message in the Partition): when the message is appended to the Partition, it will be assigned an Offset. The Partition will maintain the Offset of each GroupId, which records the consumption position of different consumer groups. Although a consumer group has multiple consumers, they can only consume the messages in their assigned Partition in order.
Replica (copy): Each Partition has several copies, a Leader, and several Followers, similar to master-slave, requests usually only deal with the Leader, and the Follower is only responsible for backup
As long as you understand these terms, the difficulty of getting started with Kafka will decrease exponentially!